关于知识工程和自然语言处理的各种概念整理
最近在参与一个数据清洗和知识管理系统的项目,主要负责各种技术路线的撰写。说实话写这些挺累的,不过撰写过程中加固了对一些以前不了解的细节知识的理解,尤其是一些概念什么的。我在这里整理一下。
一、 知识建模相关概念
知识建模涉及到的概念包括本体层和实例层,本体通常手工构建,实例通常自动化抽取。
1. 本体建模
定义:本体建模是复杂知识重构的过程,其核心是确定所构建的问题与范围,明确领域概念、约束条件以及概念间的关系。
(本体的定义:本体是共享概念模型的明确的形式化规范说明 - by Studder)
本体构建主要有三种方式:手工构建本体,复用已有本体,自动构建本体。
其中,手工构建本体可采用常用软件Protégé工具进行构建。
2. 实例建模
定义:实例建模即可理解为向定义好的本体模型中添加数据。一般采用RDF三元组的格式插入。
二、知识获取相关概念
知识获取涉及到的概念有知识获取、知识抽取和信息抽取。
1. 知识获取
定义:知识获取是组织从某种知识源中总结和抽取有价值的知识的活动。知识获取强调的是获取知识的一种活动,包括从结构化、半结构化和非结构化的信息资源中提取出计算机可理解和计算的结构化数据,以供进一步分析和利用。其范围包括知识抽取和信息抽取。
2. 知识抽取
定义:从不同来源、不同结构的数据中进行知识提取,形成知识(结构化数据)存入到知识图谱。
3. 信息抽取
定义: 从自然语言文本中抽取指定类型的实体、关系、事件等事实信息,并形成结构化数据输出的文本处理技术。
在自然语言处理技术中,知识抽取与信息抽取概念近乎等价。
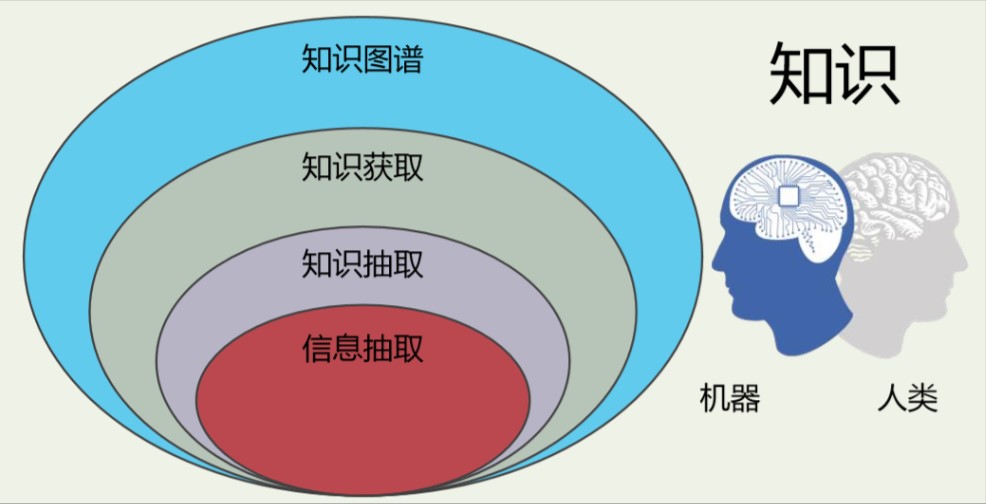
下图所示为知识、知识图谱、知识获取、知识抽取、信息抽取之间的层次关系:
三、自然语言处理相关概念
涉及命名实体识别、关系抽取、属性抽取、事件抽取、实体链接、实体消歧等。
1. 命名实体识别
定义:指识别文本(非结构化数据)中具有特定意义的实体,主要包括人名、地名、机构名、专有名词等,以及时间、数量、货币、比例数值等文字。
2. 关系抽取
定义:从文本中抽取出实体之间的关系。比如从句子“达芬奇绘制了蒙娜丽莎”中,我们可以抽取出(达芬奇,画家,蒙娜丽莎)这样一个关系三元组。
3. 属性抽取
定义:从不同信息源中采集特定实体的属性信息,例如针对某个公众人物,可以从网络公开信息中得到其昵称、生日、国籍、教育背景等信息。
(属性抽取较之实体识别、关系抽取的难点在于,除了要识别实体的属性名还要识别实体的属性值,而属性值结构也是不确定的,因此大多研究都是基于规则进行抽取,面向的也是网页,query,表格数据等等。)
4. 事件抽取
定义:从自然语言文本中抽取指定类型的事件以及相关实体信息,并形成结构化数据输出。
(事件抽取在商业、军事等领域的情报工作中应用非常广泛。事件抽取任务可分解为4个子任务: 触发词识别、事件类型分类、论元识别和角色分类任务。)
5. 实体链接
定义:将非结构化数据中的表示实体的词语(即所谓mention,对某个实体的指称项)识别出来,并将从知识库(领域词库,知识图谱等)中找到mention所表示的那一个实体。
6. 实体消歧
定义:一个实体名可能表示现实中的多个实体,实体消歧就是根据上下文确定该实体具体指的是现实中的哪个实体。
四、SPARQL 与 SQL
1. SPARQL
SPARQL是为RDF开发的一种查询语言和数据获取协议,它是为W3C所开发的RDF数据模型所定义,但是可以用于任何可以用RDF来表示的信息资源。简单来说SPARQL就是为对RDF数据的操作语言包括查询、插入、删除、更新等。
SPARQL是对知识模型进行操作的。
2. SQL
SQL(结构化查询语言)是一种数据库查询和程序设计语言,用于存取数据以及查询、更新和管理关系数据库系统。
SQL是对关系数据库进行操作的。