Insight into PyTorch.nn: Parameter vs. Linear vs. Embedding
这篇文章我也有放在medium上
In a recent PyTorch practice, I used the torch.nn.Parameter() class to create a module parameter but found the parameter was initialized with diminutive values like 1.4013e-45, which brought about very strange returned results. I replaced torch.nn.Parameter() with torch.nn.Linear() later, and surprisingly found the initialized values not odd anymore and the returned results reasonable.
I want to find an explanation for this. What do nn.Parameter() and nn.Linear() accurately do after being called? And what are the differences between them, and furthermore, nn.Embedding(), these frequently-used parameter building modules?
nn.Parameter
weight = torch.nn.Parameter(torch.FloatTensor(2,2))
This code above shows an example of how to use nn.Parameter() to create a module parameter. We can see weight is created using a given tensor, which means the initialized value of weight should be the same as the given tensor torch.FloatTensor(2,2). Now I understand the diminutive values I got are original from the given tensor! Let’s move on, what’s the value we get using torch.FloatTensor().
a = torch.FloatTensor(2,2)
print(a)
>> tensor([[4.6837e-39, 9.9184e-39],
[9.0000e-39, 1.0561e-38]])
Extremely small values in all elements! Near to 0.
In the online official guide, it says ‘torch.Tensor() is just an alias to torch.FloatTensor()’. And from the torch for numpy users notes, it seems that torch.FloatTensor() is a drop-in replacement of numpy.empty().
Now, all make sense. torch.FloatTensor(2,2) will return an empty tensor. All elements are diminutive, near to zero. That’s why I got the odd results with nn.Parameter() (Actually, it’s not about nn.Parameter(), but the given tensor).
nn.Linear
The way to create parameters using nn.Linear() is a little different. From the official guide online, the way to instantiate is below,
CLASS torch.nn.Linear(in_features, out_features, bias=True)
We can set bias to False to make nn.Linear() perform like a simple matrix transformation. In my case, I used
weight = torch.nn.Linear(2, 2, bias=False)
Then, what’s about the initialized values? From the official source code,

The only additional step in init() is self.reset_parameters() , compared to what nn.Parameter() does. nn.Linear() uses kaiming_uniform to uniforms its weight, rather than simply using an empty tensor as weight.
nn.Embedding
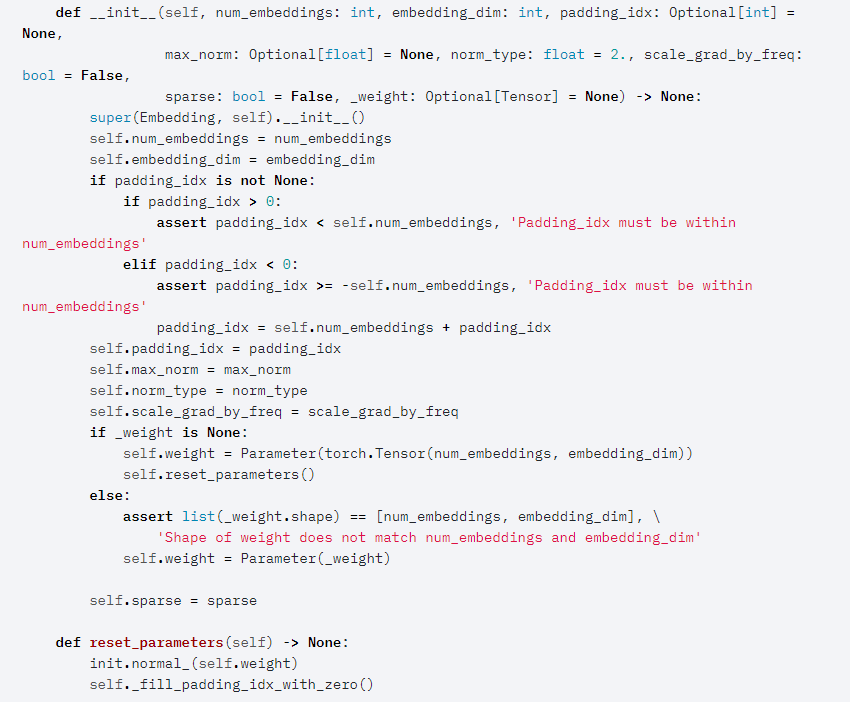
nn.Embedding() creates a simple lookup table that stores embeddings of a fixed dictionary and size. This module is often used to store word embeddings and retrieve them using indices. The input to the module is a list of indices, and the output is the corresponding word embeddings.
To create a nn.Embedding() parameter, a typical instance is:
weight = nn.Embedding(num_embedding, embedding_dim)
Just num_embedding and embedding_dim are essential. So what does nn.Embedding() do in its initialization process? In the official code, it also uses nn.Parameter() to create the weight. Note that as same as what happens in nn.Linear(), the weight value is reset as well. To be specific init.normal_() method is used to fill the weight tensor with values drawn from the normal distribution.
Conclusion
So as a conclusion, nn.Parameter() receives the tensor that is passed into it, and does not do any initial processing such as uniformization. That means that if the tensor passed into is empty or uninitialized, the parameter will also be empty or uninitialized. But nn.Linear() and nn.Embedding() initialize their weight tensors with the uniform operation and normalization operation respectively. You won’t get an empty parameter even you only give the shape.